In the past two months, I’ve created 11 new apps for myself, my family, and my coworkers, all of them made with Claude Code. It’s hard to believe the world needs more software, yet I often think “I wish [x] existed.”
Some of the things I’ve made:
- A workout tracker for my mom (a Christmas gift)
- A cli that creates podcasts from Wikipedia articles using text-to-speech from ElevenLabs
- A subscription tracker
- A website that helps you visualize the reading experience at different vocabulary levels (expanding on an idea I’ve had for years)
- A data dashboard for exploring medical malpractice cases in Nevada
- This website
I’ve started seeing more and more problems in my daily life and work as solvable. Problems like:
- “How can I design a workout plan that mom really wants to use?”
- “How do I make my reading level visualizer a lot faster and responsive?”
- “How do I make my own podcasts on the fly?”
And, I’ve started learning more about the world. For example, despite having read hundreds of medical malpractice complaints, there was more to learn. My Malpractice Explorer app unearthed an extraordinary story about the 2008 Southern Nevada Hepatitis C outbreak.
GitHub Curator
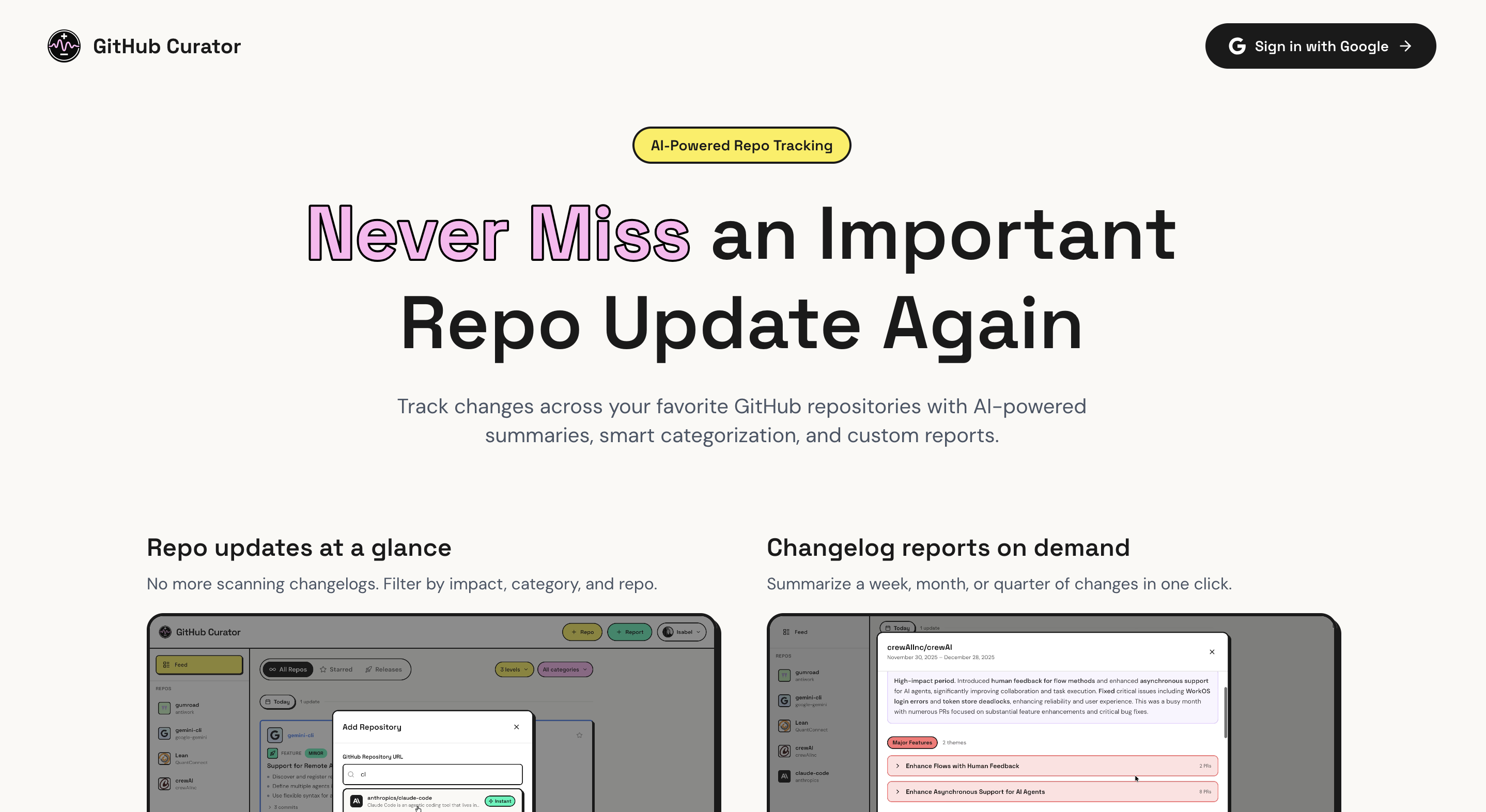
At my work, we often build courses that involve open-source repos. It can be a challenge to keep up with all the updates, and understand which updates even matter. Although GitHub does have its own “Feed” section, it’s intended more for social discovery rather than following updates.
I developed GitHub curator with two main features:
- Subscribe to repos & see a feed of AI-summarized updates categorized into major, minor, and patch (plus releases)
- “I want to see how the crewai open source library evolves over time.”
- Create reports for particular time periods
- “I want to see how Claude Code changed between December 1st and now.”
Why vibe coding?
This was the first vibe-coded app I created that truly got me hooked. Building with an API makes the data easy to display and manipulate, and you can focus on the fun parts - making it look good, and making it useful (rather than fiddling around with the data … more on that in the next section).
Several coworkers have asked me how I got the UI to look so pretty. My top two tips are:
- Know the name of the style you’re going for. GitHub Curator’s style is called “neobrutalism” (notably also used by Gumroad). You can browse styles using the Aesthetics wiki
- Provide Claude Code with a screenshot of the style you’re going for. You can use a website you’re already familiar with, or you can browse Dribbble for more ideas.
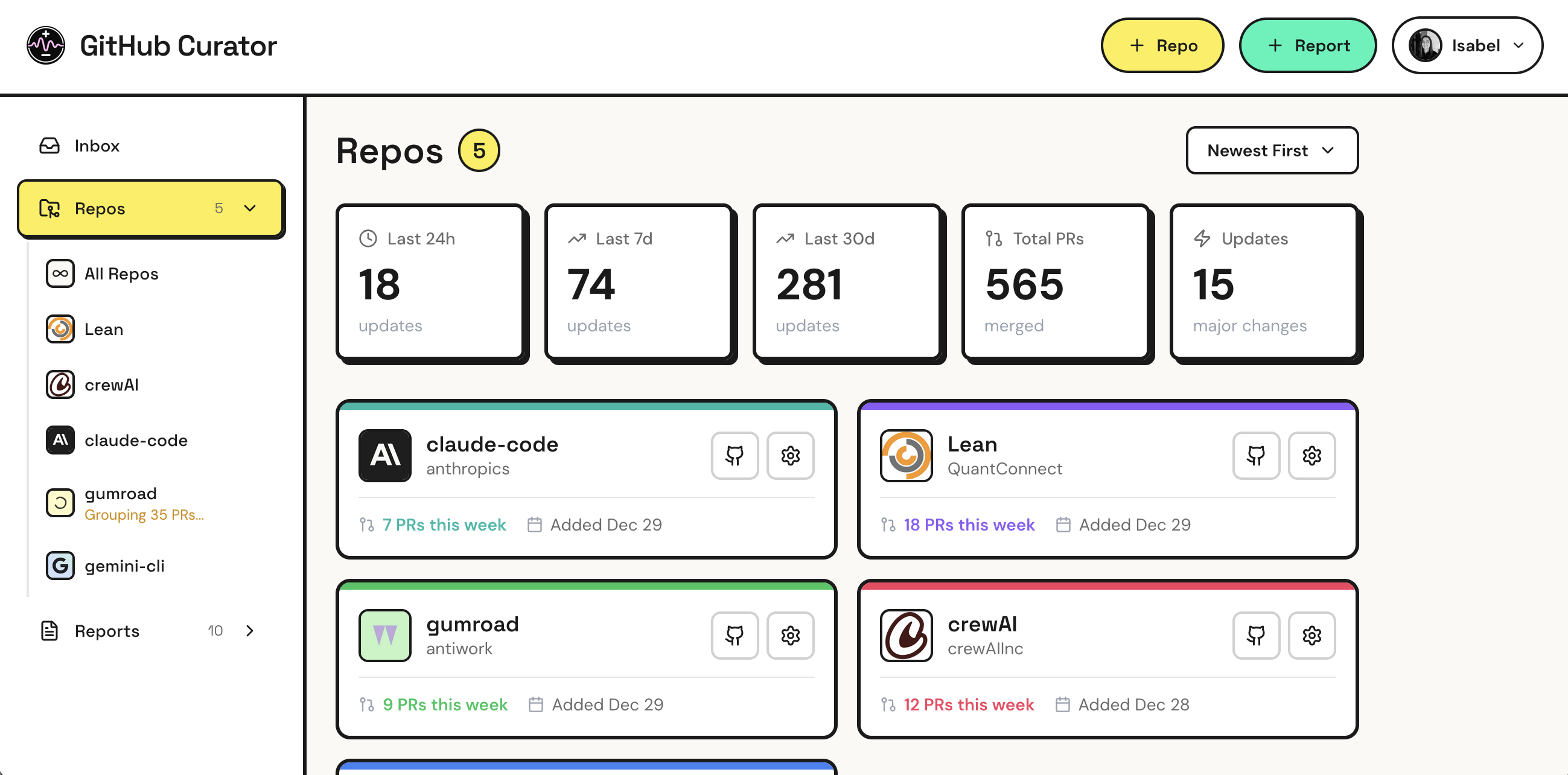
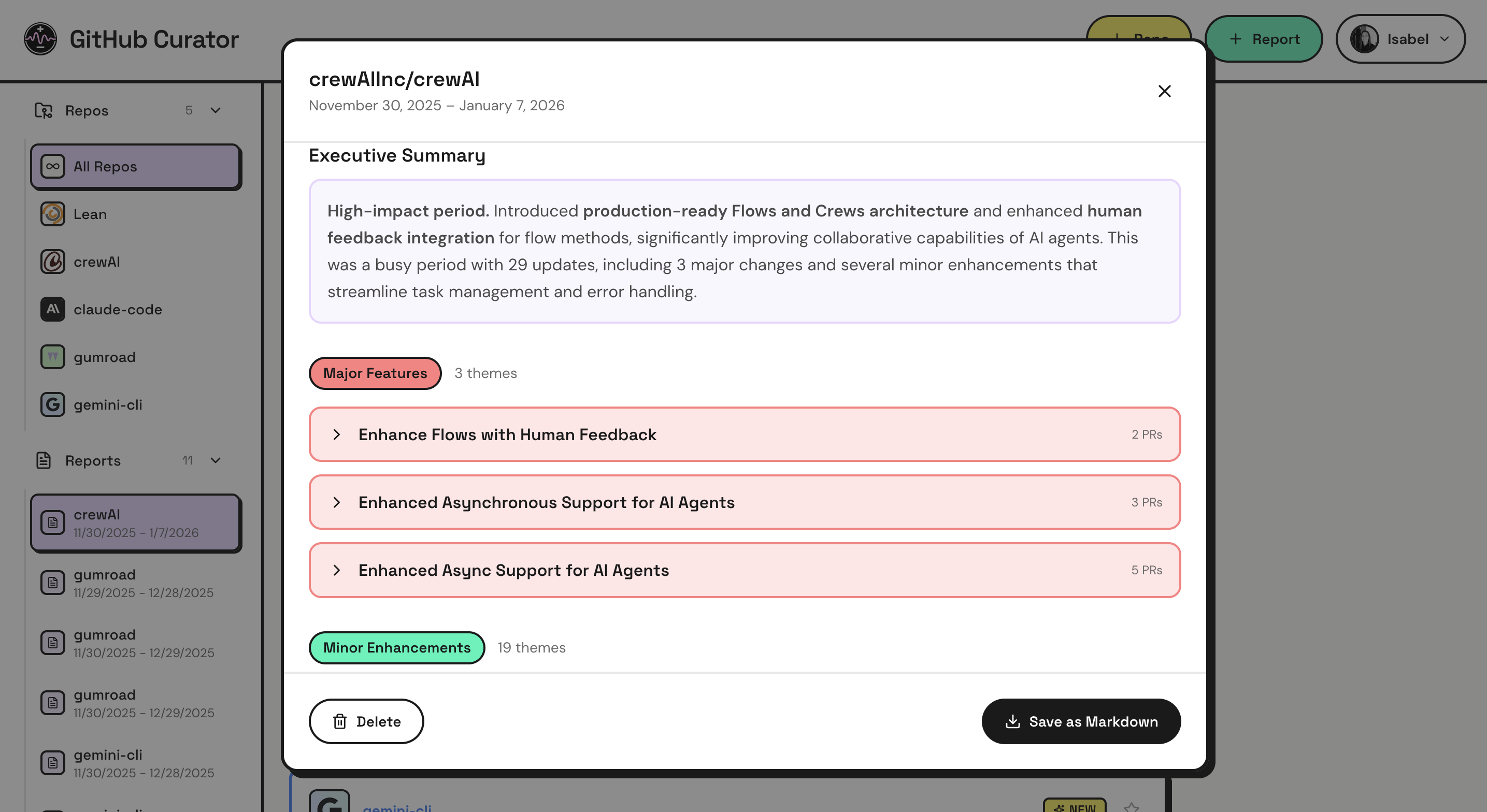
I also used AI to iterate on the sidebar structure. As I added new features, there was a big temptation to add tons of quick-access feeds and buttons to the sidebar. But, it quickly got unwieldy (I despise scrollable sidebars). I asked Gemini to develop user stories for the app, then critique the sidebar and make recommendations based on those stories as well as best practices.
Nano Banana can also draw up UI versions with different specifications, which can help you ideate quickly without changing the code. One pro tip is to ask for many “completely different approaches” in one image (i.e. one in each quadrant), which saves on costs/rate limits.
Nevada Medical Malpractice Explorer
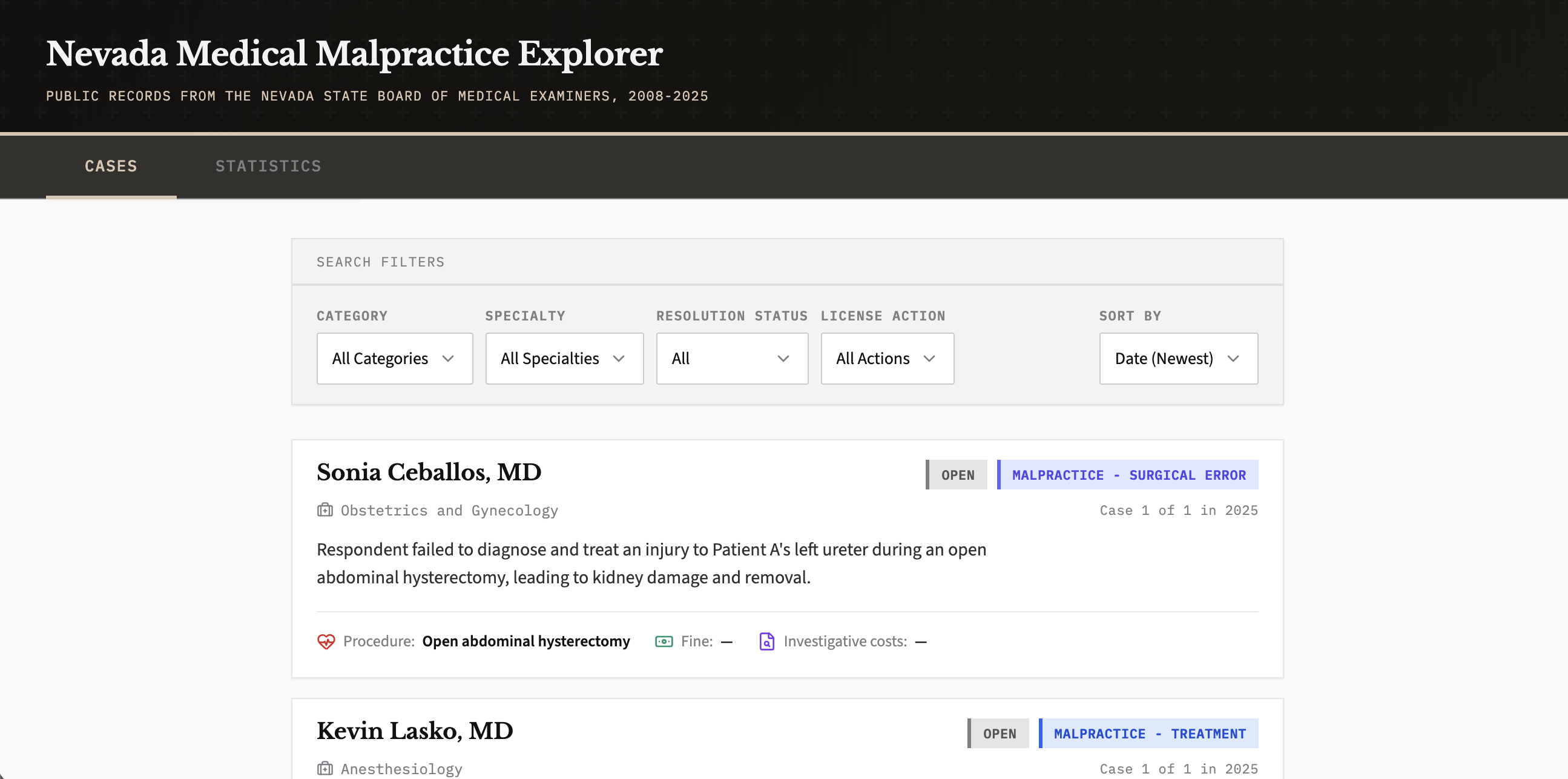
(This one is more in progress, but it’s a longer-term project and I’ve learned a lot from it.)
If you know me, you may have heard me talk about medical malpractice claims. Since discovering that the Nevada Board of Medical Examiners makes all claims, settlements, findings of fact, and so on public, I’ve obsessively read all of them. Aside from sometimes containing wild stories that would feel out of place even in Grey’s Anatomy, they give you a sense of what to pay attention to when you get medical care.
Why vibe coding?
These records present the absolute perfect vibe-coding project.
- The topic completely sucks me in.
- Because the documents are so dense, there are incredible discoveries waiting to be unearthed.
- One settlement with an uncharacteristically large $15,000 fine led me to discovering the 2008 Southern Nevada Hepatitis C outbreak caused by poor anesthesia practices in an outpatient surgery center.
- Once the data is extracted from its source PDFs (which was admittedly a huge challenge), fast iteration can surface a lot of interesting charts, trends, and figures.
Cool insights
I’m still in the process of developing the app, but I’ve discovered a few really interesting insights:
- The board has:
- Collected over $3,000,000 in investigation costs since 2011
- Levied an average of $74,000 in fines each year
- Assigned over 215 years of probation time
- Assigned over 3,000 hours of CME time (continuing education)
- The median fine is $2000
- Cases have been resolving much faster over time.
- In 2008, median resolution time was 351 days
- In 2020-2021, the median was just 90 days (!!)
- The vast majority of cases result in a public reprimand, and a suspension or revocation is rare
- Most malpractice cases track with the largest specialties & major surgeries, most notably obstetrics and anesthesiology
Main challenge & how I approached it
The main challenge in creating a clean, easy-to-use interface is that the NBME only publishes scanned PDFs, which do not contain selectable text. I developed the following pipeline to process the pdfs:
- Scrape the PDF from the website, as well as its metadata
- Detect the type of document via the file name (complaint, resolution, license-only action, or other)
- OCR the document and extract its text using
ocrmypdf- rotate, deskew, and clean - Clean the text to remove OCR artifacts like line numbers and page separators
- Extract key info from documents. Each type of document has its own fields, and amended complaints go through a special branch to get a summary of the differences from their original.
- Link complaints and resolutions. The system uses the case number to link them.
- Store the resulting text, metadata, and LLM-extracted info in the appropriate MongoDB collection.
I initially batch-downloaded and OCR’d everything, generating each step of the pipeline as I went; later, I used Claude Code to develop a unified script to handle all known edge cases. (Claude Code is great at refactoring.)
The downside of vibe coding for a project like this with ethical implications is that I don’t have 100% trust in the data right now. I hand-audited many of the LLM summaries and found them incredibly accurate, except for the “charges dismissed” section in complaints - which is important to get right!!! If I had to do it again, I would work out PDF storage first (probably with Cloudflare R2), and keep traces of everything, ideally with each pass having its own id so that you can audit the pipeline more easily.